
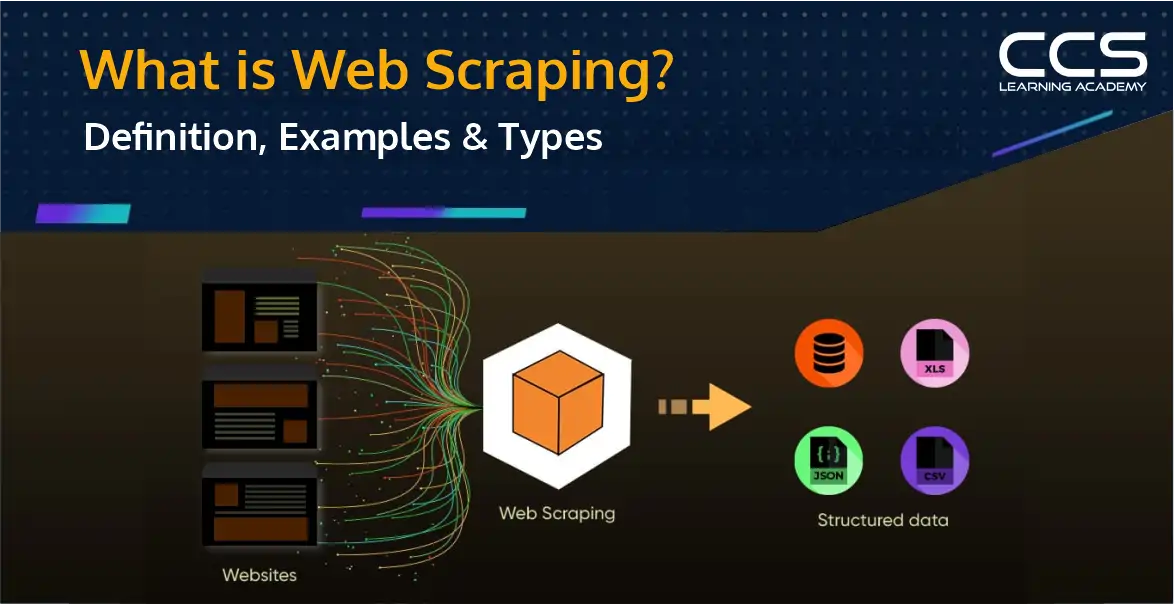
Web scraping is the automated process of extracting data from websites. Learn the definition, uses, and different types of web scraping for data collection and analysis.
Last year, I was working on a market research project that required tracking product prices across multiple e-commerce websites. Every day, I manually checked different pages, copied data into spreadsheets, and updated reports. It was exhausting.
One day, a colleague introduced me to web scraping – an automated way to collect data from websites. With just a few lines of code, I was able to extract hundreds of product prices within minutes. What took me hours before now took seconds. That’s when I realized the power of web scraping and how businesses, researchers, and analysts use it to gather, analyze, and leverage data for smarter decision-making.
In this guide, we’ll break down web scraping in simple terms—what it is, how it works, where it’s used, and what ethical guidelines to follow.
What is Web Scraping?
Think of web scraping like a super-efficient assistant that browses the internet for you, finds the information you need, and organizes it neatly into a spreadsheet or database. Instead of manually copying and pasting data from different web pages, web scraping automates the process and helps you collect information in bulk and at speed.
Some common uses of web scraping include:
- Tracking competitor prices to adjust your pricing strategy.
- Collecting customer reviews to analyze sentiment.
- Finding job postings to study hiring trends.
- Extracting contact details for lead generation.
If you’ve ever wondered how businesses gather so much data so quickly—web scraping is the answer.
Read more: What is Data Extraction? Examples, Tools & Techniques.
The Basics of Web Scraping
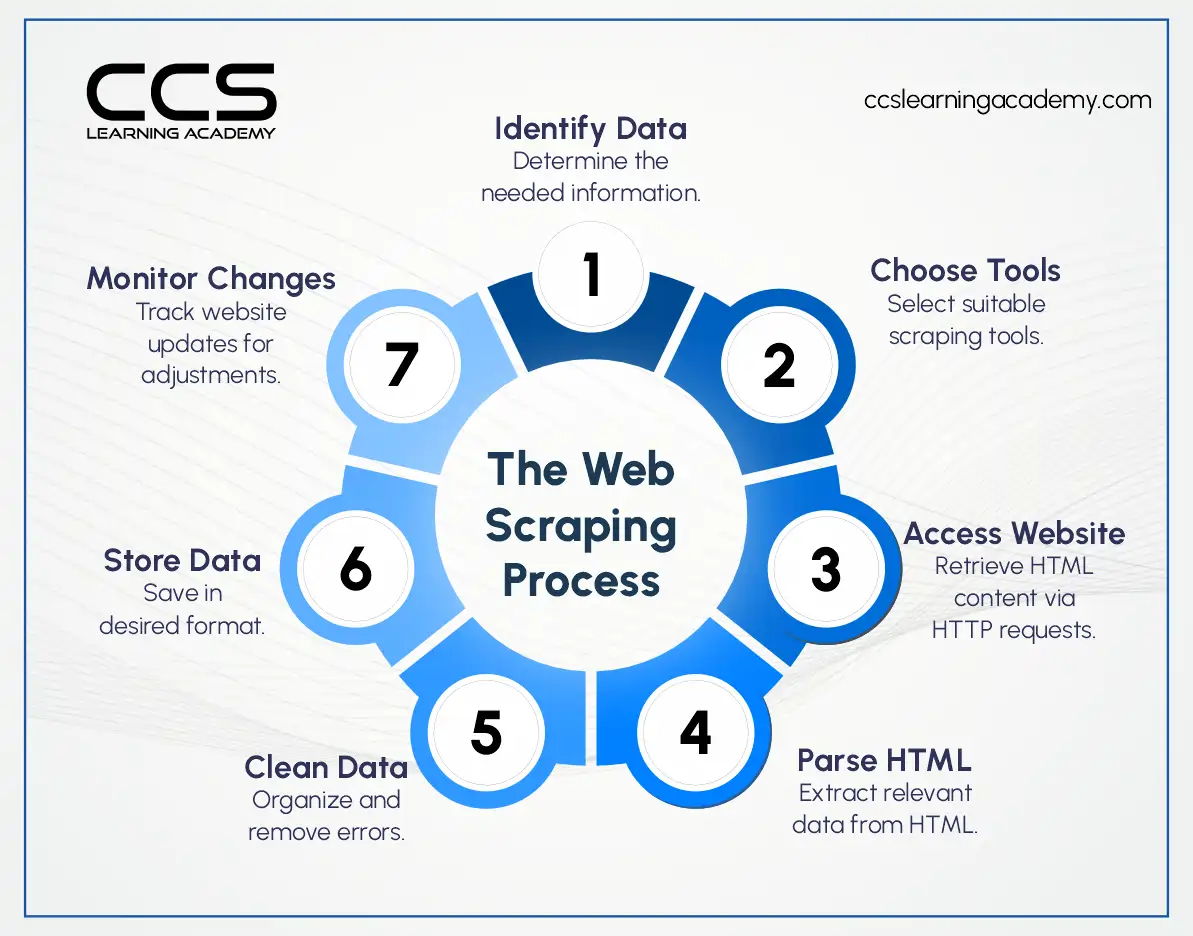
The web scraping process typically involves the following steps:
1. Identifying the target website(s)
The first step is to determine which websites contain the data you need to collect. This could be a single website or a network of related sites.
2. Analyzing the website structure
Once you’ve identified the target website(s), you’ll need to analyze the HTML structure of the pages to understand where the desired data is located. This involves using browser developer tools to inspect the page elements and identify the relevant tags, classes, and patterns.
3. Developing a scraping script
Based on your analysis of the website structure, you’ll need to create a script or program that can automatically navigate the site, locate the desired data, and extract it into a structured format (e.g., CSV, JSON).
4. Handling dynamic content
Many modern websites use JavaScript to load content dynamically, which can make it more challenging to scrape. In these cases, you may need to use more advanced tools like Selenium or Puppeteer that can render the full page and extract the necessary data.
5. Storing and cleaning the data
After extracting the data, you’ll need to store it in a database or other storage system. Depending on the quality and format of the scraped data, you may also need to clean and format it to ensure it’s ready for analysis.
Respecting legal and ethical guidelines
It’s important to be mindful of the website’s terms of service and any applicable laws or regulations when engaging in web scraping. This may involve obtaining permission, limiting the scope of your scraping, or anonymizing the data.
Read more: What is Data Wrangling? Definition, Tools, and Benefits.
Web Scraping Use Cases
Web scraping has a wide range of applications across various industries and use cases. Here are some of the most common ways that individuals and businesses leverage web scraping:
- Price Monitoring and Comparison: Web scraping can be used to monitor and compare prices across different e-commerce websites, allowing businesses to stay competitive and consumers to find the best deals.
- Market Research: By scraping data from industry websites, social media, and online forums, businesses can gather valuable insights about consumer trends, competitor activities, and market opportunities.
- Lead Generation: Web scraping can be used to gather contact information, such as email addresses or phone numbers, from websites, which can then be used for targeted marketing and sales outreach.
- News and Content Monitoring: Individuals and organizations can use web scraping to stay up-to-date on the latest news, trends, and developments in their industry by automatically extracting and aggregating content from various online sources.
- Sentiment Analysis: Web scraping can be used to collect and analyze customer reviews, social media comments, and other online discussions to understand the sentiment towards a particular product, brand, or industry.
- Web Content Aggregation: Some websites and applications use web scraping to aggregate content from multiple sources, creating a centralized hub of information for their users.
- Search Engine Optimization (SEO): Search engines like Google use web scraping techniques to index and rank web pages, and businesses can use web scraping to monitor their own SEO performance and that of their competitors.
- Academic Research: Researchers in fields like social sciences, economics, and computer science often use web scraping to gather data for their studies and analyses.
- Financial Data Collection: Web scraping can be used to collect financial data, such as stock prices, market trends, and economic indicators, from various online sources.
- Real Estate Data Extraction: Real estate professionals can use web scraping to gather data on property listings, sales, and market trends from real estate websites and portals.
These are just a few examples of the many ways that web scraping can be used to gather and leverage data from the internet. As the amount of information available online continues to grow, the demand for efficient and effective web scraping solutions is likely to increase.
Read more: Top 17 Must-Have Data Scientist Skills You Need.
Types of Web Scrapers
Web scrapers can be categorized in various ways, based on their underlying technology, level of complexity, and intended use. Here are some of the most common types of web scrapers:
1. Browser Extension or Plugin
Browser extensions or plugins are web scrapers that are installed as add-ons to web browsers, such as Chrome, Firefox, or Safari. These tools often provide a user-friendly interface for selecting and extracting data from web pages, and they can be particularly useful for small-scale or one-off scraping tasks.
Examples of browser extension web scrapers include:
- Web Scraper (Chrome)
- Scraper (Firefox)
- ParseHub (Chrome and Firefox)
2. Desktop Software
Desktop software-based web scrapers are standalone applications that can be installed on a user’s computer. These tools typically offer more advanced features and customization options compared to browser extensions, making them better suited for more complex or large-scale scraping projects.
Examples of desktop software web scrapers include:
- Scrapy (Python)
- Selenium (multi-language)
- Octoparse (Windows)
3. Cloud-Based Platforms
Cloud-based web scraping platforms are services that provide web scraping capabilities as a hosted solution. These platforms often include additional features, such as data storage, cleaning, and analysis, and they can be particularly useful for businesses that don’t want to manage the infrastructure and maintenance of a web scraper.
Examples of cloud-based web scraping platforms include:
- Zyte (formerly Scrapy Cloud)
- Apify
- Scrapinghub
4. API-Based Scrapers
Some websites provide Application Programming Interfaces (APIs) that allow users to access their data in a structured format, eliminating the need for web scraping. These API-based scrapers can be more reliable and efficient than traditional web scrapers, as they bypass the HTML structure of the website and directly access the data.
Examples of API-based scrapers include:
- Twitter API
- Google Maps API
- Yelp API
5. Specialized Scrapers
Depending on the specific use case or target website, some web scrapers are designed with specialized features or functionality. These may include:
- Ecommerce scrapers for product data extraction
- Social media scrapers for extracting user profiles, posts, and interactions
- Financial data scrapers for collecting stock prices, financial reports, and market trends
Regardless of the type of web scraper used, the underlying principles of web scraping remain the same: identifying the target website, analyzing the HTML structure, developing a scraping script, and extracting the desired data in a structured format.
Read more: How to Use AI in Data Analytics: Ultimate Guide.
Web Scraping Legality & Ethics

One of the key considerations when engaging in web scraping is the legality and ethics of the practice. While web scraping itself is not inherently illegal, there are a number of legal and ethical guidelines that should be followed to ensure compliance and avoid potential legal issues.
Legality of Web Scraping
- The legality of web scraping depends on several factors, including the method of scraping, the type of data being collected, and the terms of service of the website being scraped.
- Scraping data in violation of a website’s terms of service can lead to legal issues, as companies have the right to control how their data is accessed and used.
- Scraping copyrighted or protected content without permission may infringe on intellectual property rights.
- Collecting personal or sensitive information without user consent can violate privacy laws, such as GDPR or CCPA.
- Publicly available data that is not subject to copyright or privacy restrictions may be legally scrapped under fair use provisions, but the specific legal context should be verified.
Ethical Web Scraping Practices
- Obtain permission from website owners when necessary and adhere to their terms of service.
- Respect privacy regulations and avoid collecting personal or sensitive data without consent.
- Be transparent about data scraping activities and the purpose behind them.
- Avoid disrupting website services or overburdening servers with excessive scraping.
- Use web scraping responsibly and for legitimate, ethical purposes that benefit users or the public.
Overall, the legality and ethics of web scraping require careful consideration of the specific circumstances. Engaging in ethical scraping practices and respecting legal guidelines is crucial to mitigate risks and foster responsible data use.
Read more: Top 10 Data Analytics Projects for Beginners.
Challenges & Limitations of Web Scraping
Challenges of web scraping
While web scraping is powerful, it comes with challenges:
Data Warehousing
Extracting data at scale can generate a large amount of information that needs to be stored. If the data warehousing infrastructure is not properly built, the searching, storing, and exporting of this data can become difficult.
For large-scale data extraction, there needs to be a well-designed data warehousing system without any flaws.
Website Structure Changes
Websites periodically update their user interfaces to improve attractiveness and user experience, which requires structural changes.
Since web scrapers are set up based on the website’s code elements at a given time, they also require frequent changes to target the correct website structure and avoid improper data scraping.
Anti-Scraping Technologies
Some websites use anti-scraping technologies to prevent bot intervention, such as dynamic coding algorithms and IP blocking mechanisms. Working around these anti-scraping measures can be time-consuming and expensive.
Quality of Data Extracted
Poor-quality data that does not meet the required standards can affect the overall integrity of the scraped data. Ensuring the quality of the extracted data in real-time is a challenging task.
Limitations of Web Scraping
Legality
The legality of web scraping is a sensitive and evolving topic. While web scraping can have beneficial uses, such as enabling search engines to index web content or providing price comparison services, it can also be misused for malicious activities like data theft, account hijacking, and denial-of-service attacks. The legality of web scraping tends to develop over time as laws and regulations adapt to this technology.
Copyright Violations and Terms of Use
Web scraping can lead to copyright violations and breaches of a website’s terms of use, which can be disruptive to a company’s business. Scraping websites without permission or in a way that violates their policies can have legal consequences.
Dynamic Content
Websites that use JavaScript to load content dynamically can be more challenging to scrape, as they may require more sophisticated tools like Selenium to interact with the page and extract the data properly.
Captchas and Bot Detection
Many websites employ captchas and bot detection mechanisms to prevent automated scraping. Overcoming these obstacles can be time-consuming and may require additional techniques, such as the use of proxy networks or machine learning-based captcha solving.
Ethical Considerations
While web scraping itself is not inherently unethical, the way it is used can raise ethical concerns, particularly when it comes to collecting personal or sensitive information without consent or in a way that violates privacy rights.
Read more: How to Start a Career in Data Analytics [Step-by-Step Guide.
Conclusion
In conclusion, while web scraping is a powerful technique, it is essential to approach it ethically and legally by respecting website terms of service, protecting user privacy, and maintaining transparency. By leveraging web scraping responsibly, businesses and researchers can unlock valuable insights that drive informed decision-making across various industries.
CCS Learning Academy’s data-related courses provide the essential skills and knowledge to perform web scraping responsibly, empowering you to gather valuable insights and drive informed decisions in any industry. With CCS Learning Academy, you’ll build a strong foundation in ethical data practices, enabling you to harness the full potential of data-driven analysis.




