

Data engineering is taking off, and the demand for skilled data engineers is skyrocketing. As projections indicated, in 2024, the average data engineer salary peaked at $110,000, reflecting a 3.3% surge from 2023. With data analysis driving critical business decisions across all industries, companies are on the lookout for professionals well-versed in the latest data engineering tools and technologies to make sense of their mounting information assets.
In this article, we run down 10 must-have tools that any forward-looking data whiz needs to have under their belt in 2025. Whether you’re just ramping up your skills or brushing up on the newest additions, this list will ensure you’re equipped to take advantage of the field’s rapid growth. The anticipated 21% increase in data engineering jobs from 2018 to 2028 foreshadows bright prospects for those who commit to staying on top of the latest and greatest developments.
From stalwarts like Python and SQL to cutting-edge options like Tableau and dbt, we break down the basics of what each tool brings to the table. You’ll learn how they fit together in real-world data pipelines and workflows. With data engineer roles ranging from constructors and monitors to optimizers and innovators, our lineup offers insight into which tools align with different responsibilities.
So rev up your analytical engines and get ready to soak up the top 10 data engineering tools you must master to elevate your career in 2025. The future looks bright, so let’s dig in!
What Is Data Engineering?

Data engineering refers to the concepts, tools, and techniques involved in designing, building, and maintaining data pipelines that collect, transform, and store data for analytical use cases. As data volumes and sources continue to ramp up exponentially, data engineers have stepped up to manage the complex behind-the-scenes work needed to structure and organize expansive data sets for business teams to glean actionable insights from.
They stitch together processes to ingest data from diverse systems, clean up errors, connect disparate data sets, develop models, and pipe the refined data into downstream platforms for consumption.
Data engineers architect robust systems that scale up to accommodate tremendous data flows and ever-changing business demands. Their work powers essential analytics applications and data products that companies have come to rely on to drive decisions.
In many ways, data engineers lay the groundwork to funnel raw data into pipelines that ultimately feed advanced analytics and algorithms further down the line. Their specialized skills in taming “big data” chaos make them invaluable to managing the data lifecycle from origins to outcomes. As data’s role becomes more pivotal in every industry, data engineers will continue stepping up to meet enterprise data needs.
What are Data Engineering Tools?
Data engineering tools refer to the various software applications, libraries, services, and frameworks that data engineers utilize to carry out their responsibilities. As data infrastructures scale up in complexity, data engineers have assembled robust toolkits to help them take on more challenging tasks with higher efficiency.
From ingestion to transformation, storage to integration, data engineers tap into specialized tools that allow them to parse immense datasets, sculpt them to user specifications, funnel them into data warehouses, make them playable across business intelligence dashboards, and more.
Leading tools empower data engineers to sync up disparate systems, monitor data pipelines, troubleshoot issues, and optimize flow rates. They lean on tools to automate manual processes for increased productivity.
Whether open-source staples like Python and Apache Spark or cloud-based platforms like Snowflake and Databricks, data engineering tools enable practitioners to model data landscapes, erect structural foundations, oversee smooth operations, and build bridges between raw inputs and business-ready outputs.
As data volumes and use cases continue to expand, versatile tools assist data engineers with scaling up existing infrastructure and information flows to meet enterprise analytics needs.
Top 10 Data Engineering Tools You Must Learn
As we enter 2025, the field of data engineering is still evolving. This list highlights the top 10 data engineering tools and gives insights into the tools that are currently important and will likely be important in the future. This carefully chosen selection is a guide for data engineers who want to stay updated in their field.
1. Python
Python has catapulted to popularity among data engineers thanks to its versatility, ease of use, and ability to adapt to any data scenario. As an interpreted, object-oriented language, Python allows data engineers to rapidly build out and iterate on data pipelines. Its simple syntax cuts down on boilerplate coding, enabling quicker development.
Python has ramped up in usage for ETL processes thanks to native libraries like Pandas, which bolts on capabilities to parse many data formats and effortlessly wrangle unwieldy datasets down to size. NumPy and SciPy also step up for numerical computing and exploratory analysis at scale.
For machine learning applications, Sklearn comes stocked with algorithms to put models into production with Python code. The flexibility to tackle the full data workflow from ingestion to analytics makes Python a one-stop-shop for data engineers. Its extensive libraries also allow it to sync up with the latest data tools and platforms.
2. SQL
SQL, which stands for Structured Query Language, underpins data management across relational databases with its intuitive syntax for slicing and dicing data at will. Whether pulling, manipulating, analyzing, or pushing around data, SQL enables direct access without compatibility issues.
Data engineers rely on SQL to not only speak the lingua franca across SQL variants from vendors like Oracle, MySQL, and Microsoft but also translate data requests between humans and machines. SQL’s versatility makes it a must-have arrow in any data engineer’s quiver for extracting insights from relational database structures with targeted querying. Plus, SQL skills pair well with many other tools to move data from warehouses to production platforms.
3. PostgreSQL
PostgreSQL has emerged as a leading open-source relational database thanks to its proven reliability, security and high performance over decades of real-world testing. Backed by an active open-source community, PostgreSQL offers enterprise-grade features for transactional integrity, sophisticated authentication and granular user permissions. Its scalability makes PostgreSQL a common repository for streaming high volumes of data from operational systems and data pipelines.
Data engineers also leverage PostgreSQL for its spatial extensions that supercharge location-based queries. Purpose-built indexing, database partitioning features and support for complex workloads bolster PostgreSQL’s versatility as a data engineering toolbox.
4. MongoDB
MongoDB has stormed the database scene as an intuitive document-based alternative to traditional SQL databases that maps neatly to code objects for faster development. By encoding data in JSON-style documents rather than tables and rows, MongoDB accelerates working with data in modern programs. Its flexible schema skips rigid data modeling for dynamic iterations.
Automatic indexing under the hood powers lightning-fast queries, while native aggregation streamlines analytics. MongoDB’s horizontal scalability allows seamless expansion to accommodate influxes of real-time data across nodes.
With robust built-in replication, auto-failover, and backup mechanisms, MongoDB enables always-on availability critical for data-intensive applications. For data engineers building apps leveraging big data, MongoDB brings together versatile modeling, intuitive syntax, and industrial-strength management of distributed data loads.
5. Apache Spark
Apache Spark has ignited the big data landscape as a lightning-fast unified analytics engine for large-scale data processing. Its in-memory cluster computing framework ties together data engineering tasks for ETL, SQL analytics, machine learning, and graph processing at scale. Spark’s speed stems from circumventing disk bottlenecks by caching datasets across a cluster for parallel querying.
Data engineers tap Spark to crunch petabytes of data with ease and real-time stream processing via Spark Streaming. Spark ML powers training driverless machine learning algorithms at scale while Spark GraphX pathfinds hidden insights through relationship mapping.
With renowned scalability and versatility to handle even the most demanding workloads, Apache Spark has become a cornerstone tool for data teams. Its unified framework future-proofs data pipelines with an expanding library of modules plugging into the core engine.
6. Apache Kafka
Apache Kafka provides real-time data piping capabilities to gush massive message streams between systems with minimal latency. Its publish-subscribe messaging system acts as a critical broker between data producers and consumers to decouple systems and prevent slowdowns.
Kafka’s scalable architecture absorbs tremendous data loads with high-throughput partitioning across nodes in a cluster. Messages queue up in Kafka’s fault-tolerant storage layer for processing in parallel and at receiver pace. Kafka Streams and Kafka Connect add stream processing and integration capabilities to unlock insights and normalize data efficiently for downstream analytics.
Data engineers rely on Apache Kafka’s enterprise-grade messaging and queuing functionality to rapidly relay data at scale and unlock more value through event-driven architectures.
7. Amazon Redshift
Amazon Redshift positions itself as one of the most powerful, scalable, and cost-effective cloud data warehouse solutions for crunching big data. It simplifies provisioning and managing petabyte-scale data warehouses with its cloud-based infrastructure optimized for high-performance analytics.
Redshift automates hardware provisioning, software patching, and cluster configurations, allowing data teams to focus strictly on loading, transforming, and optimizing data flow through the warehouse. Its massively parallel processing (MPP) architecture executes queries in tandem across all nodes for blazing-fast analysis on billions of rows in seconds.
Backups run continuously without affecting performance while Redshift Spectrum stitches together extra capacity from other data sources on demand.
8. Tableau
Tableau empowers a wide spectrum of business users to engage with data through its rich gallery of interactive business intelligence dashboards. With its intuitive drag-and-drop interface, Tableau enables data visualization at scale for actionable analytics. Users can rapidly connect data sources before drilling into dimensions through charts, graphs, and maps.
Boundless customization options help tailor visualizations to any analytics need or audience while staying true to the numbers. Tableau relieves data teams from report generation duties so they can channel energy into harnessing data centrally for broad consumption. Seamless integration with leading warehouses like Snowflake makes Tableau a trusted data democratization partner.
9. Segment
Segment offers the connective tissue for managing customer data infrastructure through one streamlined API integration. Their platform snaps together data from all user touchpoints into a centralized warehouse while normalizing formats for flexibility.
Lean data teams can swiftly consolidate disparate data streams for a unified view of the customer without heavy lifting. Segment puts ultimate control over data flows and permissions in the hands of engineers while managing pipelines under the hood.
With data readily consumable for tools like Mixpanel, Braze and Amplitude via Segment, engineers speed up building user analytics and personalization to elevate the experience. As information silos transform into interconnected lakes, Segment brings order and structure to convoluted digital data trails.
10. Data Build Tool (dbt)
dbt transforms data workflow by enabling analytics engineers to develop modular data transformation code for the modern cloud data stack. With dbt’s open-source framework built on SQL, engineers construct reusable data models and analyses using developer-friendly tools for testing and documentation. dbt handles orchestrating model deployment across platforms while guaranteeing interoperability so teams can spend more cycles on innovation.
Backed by a robust community constantly adding to its toolset, dbt streamlines engineering pipelines from warehouses to customer-facing applications. Its ability to bolster visibility, productivity, and collaboration unlocks more analytic value from data investments. As complexity mounts across analytics stacks, dbt brings sane structure along with the agility to build rapidly.
Why Pursue a Career in Data Engineering?
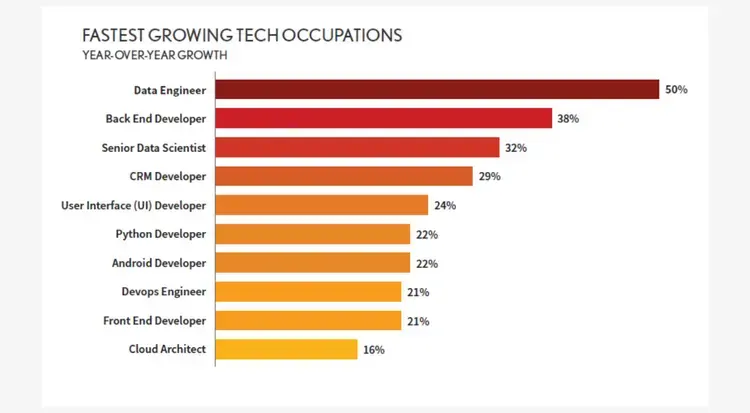
Here are some of the key reasons to pursue a career in data engineering:
New Field
Data engineering has skyrocketed to the forefront of tech as organizations scramble to make sense of massive data volumes flooding their systems daily. This hypergrowth, still in its infancy, signals ample career upside for those looking to plant their flag early as a recognized authority.
Seasoned engineers can parlay existing skills into data, while newcomers can break in with just analytical abilities. Getting in now, while specialization widens, means sidestepping competition down the line.
Job Stability
As data underpins more critical business functions by the day, data engineers find their roles increasingly safeguarded as indispensable. Forward-thinking companies funneling resources into advanced analytics make data talent a top priority.
With skyrocketing demand meeting scarce supply industry-wide, data engineers claim strong job security thanks to a stark talent shortage that’s expected to swell in coming years.
Dynamic Responsibilities
Far from mundane, data engineering brings together cutting-edge tools and ever-evolving challenges for constant learning. As opposed to repetitive tasks, data engineers architect solutions while leveraging creativity.
Moving targets ensures no two situations are alike, thanks to shifting data volumes, tech trends, and business priorities that guarantee variety. Engineers gain broad exposure by tackling operations, analytics, and infrastructure challenges daily.
Lucrative Pay
Given the specialization and scarcity of their skill sets on top of high stakes for employers, data engineers earn some of tech’s fattest paychecks, often rivaling traditional software engineers.
Data engineering roles typically pay above-average salaries nearing or exceeding 6 figures for those with proven expertise. Increased hiring demand forecasts even sweeter payouts over time.
Conclusion
As the importance of data keeps growing each year, having the right tools can help data engineers succeed in a high-demand environment. Mastering the top 10 tools we covered will augur success as organizations increasingly bank on data-driven insights to guide strategy. Our roundup spans data ingestion, storage, processing, and visualization to equip professionals across the data lifecycle.
While the learning curve may seem daunting at first glance, perseverance promises handsome dividends for motivated individuals in terms of career advancement and skill building. For those seeking guided instruction geared specifically to data engineering’s most indispensable skills, CCS Learning Academy’s Data Analytics & Engineering Bootcamp warrants consideration.
Our acclaimed program condenses the essential data engineering methodologies, tools, and technologies into an intensive 12-week immersive course. With a live online format, professionals can level up their data engineering prowess without compromising their schedules. The comprehensive curriculum covers building and maintaining data pipelines, cloud data warehouses, database systems, ETL processes, statistical analysis, and visualization to equip learners with an end-to-end overview.
FAQs
Q1: What types of data processing frameworks are essential for Data Engineers to learn?
Data Engineers should be familiar with both batch and stream processing frameworks. Batch processing frameworks handle large volumes of data at once, while stream processing frameworks deal with continuous data in real time. Mastery of both types is crucial for developing scalable data pipelines.
Q2: Why are database management systems important for Data Engineers?
Database management systems (DBMS) are important because they provide a systematic and efficient way of storing, retrieving, and managing data. Data Engineers need to understand both SQL (relational) and NoSQL (non-relational) databases to handle diverse data storage needs effectively.
Q3: How do workflow orchestration tools benefit Data Engineers?
Workflow orchestration tools help Data Engineers automate and manage the data pipeline processes systematically. These tools enable scheduling, monitoring, and dependency management of various data jobs, ensuring that complex data workflows are executed reliably and efficiently.
Q4: What role do data integration tools play in Data Engineering?
Data integration tools play a critical role in combining data from different sources, providing a unified view. They help Data Engineers extract, transform, and load data (ETL) across systems, which is essential for data analysis and business intelligence.
Q5: Why is knowledge of cloud computing platforms beneficial for Data Engineers?
Cloud computing platforms offer scalable, flexible, and cost-effective resources for data storage, processing, and analysis. Knowledge of these platforms allows Data Engineers to leverage cloud services for building and deploying data pipelines, data storage, and big data processing tasks.
Q6: How do containerization technologies support Data Engineering practices?
Containerization technologies support Data Engineering by providing consistent, isolated environments for developing, testing, and deploying applications. This ensures that data applications run reliably across different computing environments, facilitating easier scaling and deployment.
Understanding data serialization and storage formats is crucial for Data Engineers as it affects how data is stored, processed, and exchanged between systems. Efficient formats support faster data processing and lower storage costs, impacting overall system performance.
Q8: How can Data Engineers utilize machine learning platforms in their work?
Data Engineers can utilize machine learning platforms to preprocess and transform data, making it suitable for machine learning models. They also manage the data infrastructure for training and deploying models, working closely with Data Scientists to operationalize machine learning workflows.
Q9: Why are data visualization and reporting tools necessary for Data Engineers?
Data visualization and reporting tools are necessary for Data Engineers to communicate data insights effectively. These tools help in creating dashboards and reports that visualize complex data in an understandable format for stakeholders to make informed decisions.
Q10: What strategies should Data Engineers adopt to stay updated with new tools and technologies?
Data Engineers should continuously learn by following industry news, participating in forums and communities, attending workshops and conferences, and experimenting with new tools and technologies. Staying engaged with the data engineering community and pursuing ongoing education are key strategies for keeping skills current.




